下面學習如何使用 vikit-learn 訓練一個圖像分類器。我們將使用貓狗圖像數據集 OxfordIIITPet 來進行實踐操作。
我們可以使用pip工具從 github 上在線下載並安裝 vikit-learn:
pip install git+https://github.com/bxt-kk/vikit-learn.git
我們需要編寫一點腳本代碼來訓練我們的模型。
import torch
from torch.utils.data import DataLoader
from vklearn.trainer.trainer import Trainer
from vklearn.trainer.tasks import Classification as Task
from vklearn.models.trimnetclf import TrimNetClf as Model
from vklearn.datasets.oxford_iiit_pet import OxfordIIITPet
dataset_root = '/kaggle/working/OxfordIIITPet'
dataset_type = 'binary-category'
train_transforms, test_transforms = Model.get_transforms()
train_data = OxfordIIITPet(
dataset_root,
split='trainval',
target_types=dataset_type,
download=False,
transforms=train_transforms)
test_data = OxfordIIITPet(
dataset_root,
split='test',
target_types=dataset_type,
transforms=test_transforms)
首先,我們需要指定數據的存放位置dataset_root;然後,我們指定數據的類型dataset_type = 'binary-category',這表示貓狗圖像的二分類數據;另外,我們將數據分割成訓練集split='trainval'和測試集split='test'。
注意!如果本地目錄中沒有數據,那麼我們需要把download設置爲True以從網絡上下載數據。
batch_size = 128
train_loader = DataLoader(
train_data, batch_size,
shuffle=True,
drop_last=True,
num_workers=4)
test_loader = DataLoader(
test_data, batch_size,
shuffle=False,
drop_last=True,
num_workers=4)
print(len(train_loader))
我們使用 pytorch 提供的數據加載工具DataLoader實現數據加載,這裏我們設置batch_size = 128。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Model(categories=train_data.bin_classes)
task = Task(model, device)
我們使用TrimNetClf類創建了一個模型。這裏,我們需要爲模型指定分類類別的數量以及類別的名稱,爲此,我們將train_data.bin_classes的值作爲模型的categories參數值。接着,我們使用模型對象model和計算裝置對象device創建訓練任務對象task = Task(model, device)。
trainer = Trainer(
task,
output='/kaggle/working/catdog-clf',
train_loader=train_loader,
test_loader=test_loader,
epochs=20,
lr=1e-3,
lrf=0.2,
show_step=50,
save_epoch=5)
trainer.initialize()
通過設置訓練器參數,我們可以創建一個用於模型訓練的訓練器,在創建訓練器對象後,需要執行trainer.initialize()方法進行初始化。
我們對該訓練器進行了如下參數設定:
task:指定訓練任務;output:設定訓練數據輸出路徑,用於存儲 checkpoint 和日誌;train_loader:指定訓練集加載器;test_loader:指定測試集加載器;epochs:設置總共訓練多少輪;lr:設置學習率大小;lrf:設置學習率衰減因子;show_step:設置每隔多少步打印訓練狀態;save_epoch:設置每隔多少輪存儲一次 checkpoint;最後我們通過如下代碼,開始模型訓練:
trainer.fit()
當模型訓練結束後,我們會在訓練器輸出路徑同級目錄下的 logs 子目錄中看到訓練日誌:
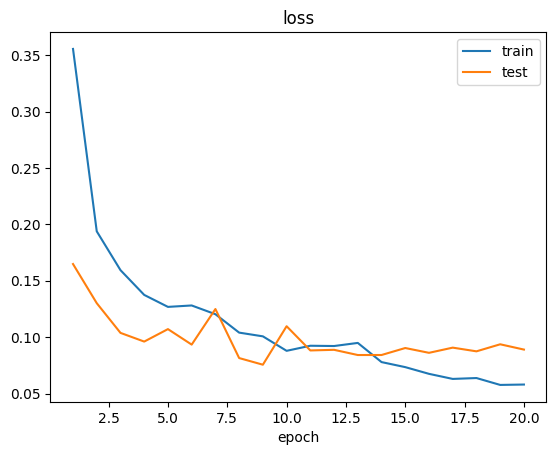
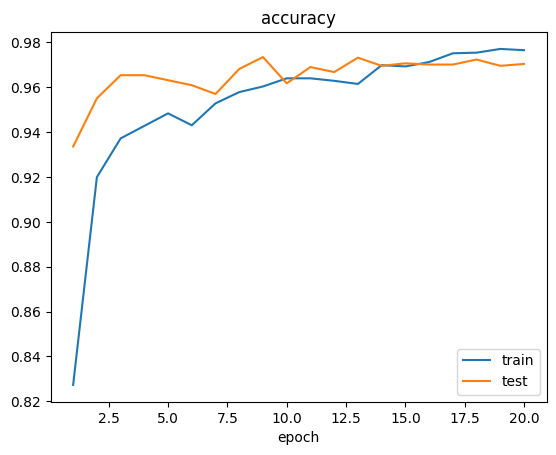
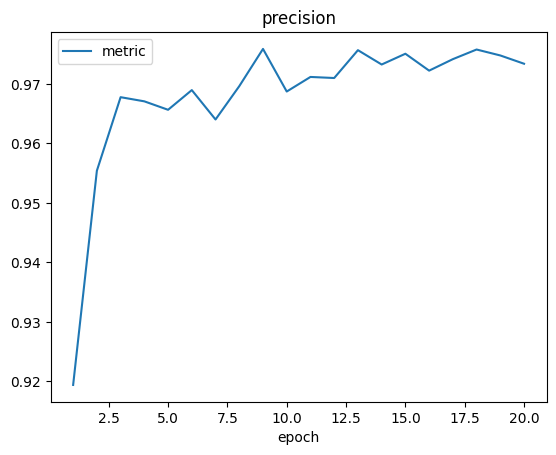
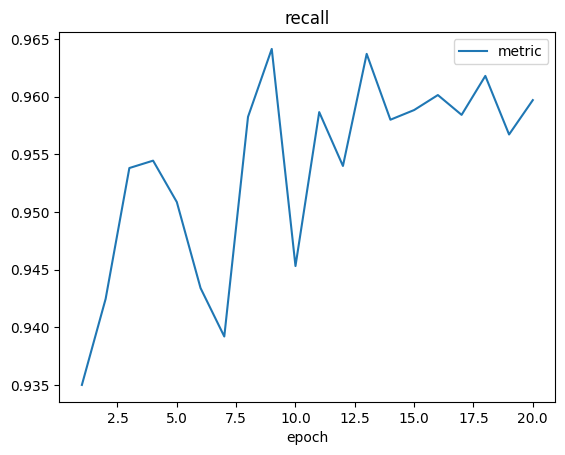
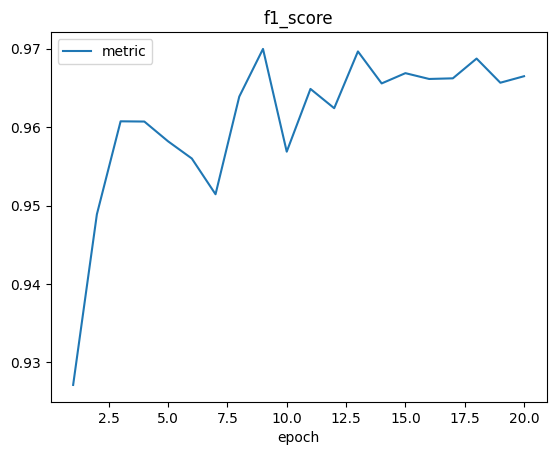
除了日誌,我們還會看到如下 checkpoint 文件:
- catdog-clf-4.pt
- catdog-clf-9.pt
- catdog-clf-14.pt
- catdog-clf-19.pt
- catdog-clf-best.pt
一般來說,我們挑選best.pt結尾的進行使用,因爲這是在測試集評估指標中得分最高的checkpoint。
在完成圖像分類器訓練後,我們就可以使用訓練好的分類器來對圖像進行自動分類了。
import matplotlib.pyplot as plt
from PIL import Image
from vklearn.models.trimnetclf import TrimNetClf as Model
from vklearn.pipelines.classifier import Classifier as Pipeline
from vklearn.pipelines.classifier import Classifier將引入流水線工具Classifier,該工具極大簡化了模型的調用。
pipeline = Pipeline.load_from_state(
Model, '???/catdog-clf-best.pt')
注意!記得將'???/catdog-clf-best.pt'替換爲你電腦中 checkpoint 文件的真實路徑。
在完成之前一系列的準備工作後,我們就可以使用如下代碼進行分類操作了:
img = Image.open('??your image path??')
result = pipeline(img)
fig = plt.figure()
pipeline.plot_result(img, result, fig)
plt.show()
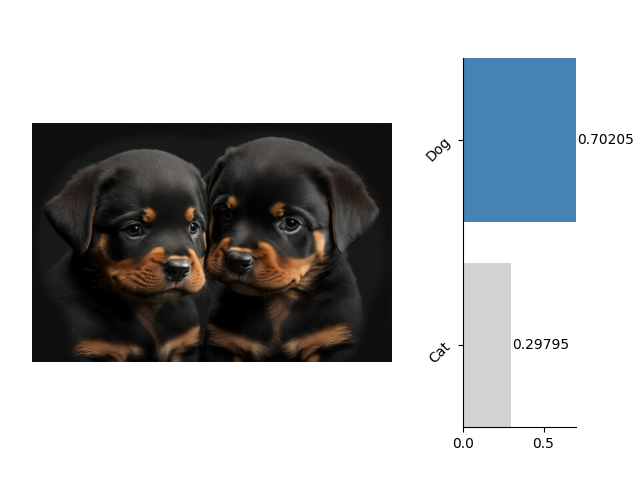
我們使用上述代碼打開了一張圖像img = Image.open('??your image path??')進行分類預測result = pipeline(img),並可視化了預測結果:
 jojowee
jojowee
